Some key points in recommendation

Summary
一、召回
TDM
-
TDM 是一种结合决策树和深度学习技术的召回策略。它通过构建一棵候选物品的层次树,利用深度学习模型按层分解预测的方式逐层向下筛选候选集,以此提升召回的效率和精确度
-
```
- 利用上一轮训练得到的各item embedding,通过k-means建立树
- 在树上,得到各层的正负样本
- 在各层上的每个正负节点上,用dnn预测ctr,𝐶𝑇𝑅𝑝𝑟𝑒𝑑𝑖𝑐𝑡=𝐷𝑁𝑁(𝐹𝑒𝑎𝑡𝑢𝑟𝑒_𝑢𝑠𝑒𝑟,𝐹𝑒𝑎𝑡𝑢𝑟𝑒_𝑛𝑜𝑑𝑒),再喂入binary cross-entropy计算loss
- 训练完毕,得到“新embedding”,返回step 1,开启下一轮训练 ```
ComiRec
-
网络结构:ActionList通过 self-attentive method 建模多 user embedding(相当于多头Self-Attentive)
-
训练阶段:item embedding 选取点积最大的 user embedding 进行训练, loss 是 negative log-likelihood
-
serving阶段:多路user embedding分别进行ANN检索,再通过 aggregation module 聚合,aggregation module 会通过 $\lambda$ 权衡 accuracy / diversity
- \[Q(u, S)=\sum_{i\in S}{f(u,i)+\lambda \sum_{i\in S}{\sum_{j\in S}{g(i,j)}}}\]
- \[\]
CB2CF
二、Rank
Learning-to-rank
-
learning-to-rank is the application of machine learning, typically supervised, semi-supervised or reinforcement learning, in the construction of ranking models for information retrieval systems.
-
Approach:
-
pointwise 每个 item 预估一个分数
-
pairwise 预估 2 个 item 哪个更加 relevant
-
listwise 给 n 个 item 排序使得总收益最大
-
PRM (Personalized Re-ranking for Recommendation)
- pairwise
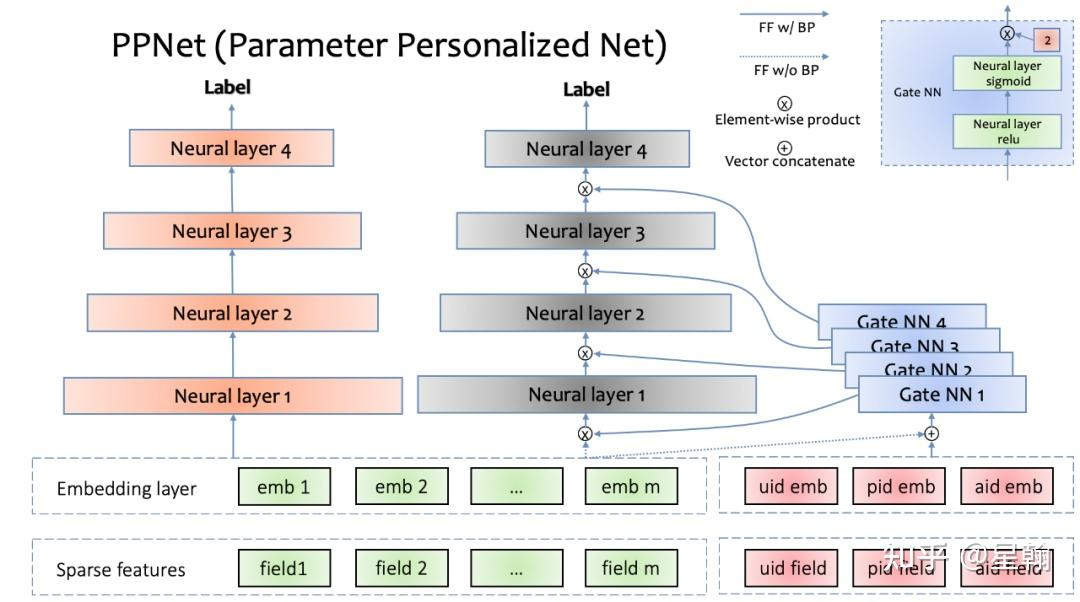
Parameter Personalized Net (PPNet)
-
PPNet 通过 Gate NN 结构达到增强用户个性化表达的能力 (uid + pid + aid)
-
训练过程中左侧所有sparse特征不接受Gate NN 的反传梯度,这样操作的目的是减少 Gate NN 对现有特征 embedding 收敛产生的影响。
-
GateNN结构共两层,第二层网络的激活函数是2 * sigmoid,默认值为1