
Reinforcement learning

Background
course: deep-rl-class
Basics
- Loop: state0, action0, reward1, state1, action1, reward2 …
- State: complete description of the world, no hidden information
- Observation: partial description of the state of the world
- Goal: maximize expected cumulative reward
- Policy: tells what action to take given a state
-
Task:
- episodic
- continuing
-
method:
-
policy-based (learn which action to take given a state)
- deterministic 给定 state s 会选择固定某个 action a: $a=\pi(s)$
- stochastic: output a probability distribution over actions
-
value-based (maps a state to the expected value of being at that state)
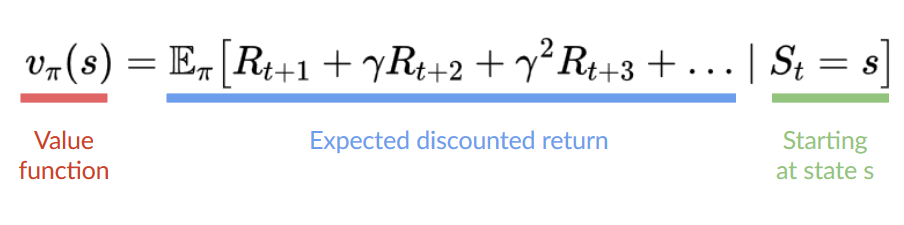 随时间 reward 有一个衰减, $\gamma < 1$
随时间 reward 有一个衰减, $\gamma < 1$- 这时 policy 是个简单的人为确定的策略
-
-
value-based methods
-
Monte Carlo: update the value function from a complete episode, and so we use the actual accurate discounted return of this episode (获得实际的一个 episode 的 reward)
- \[V(S_t) \leftarrow V(S_t) + \alpha [G_t - V(S_t)]\]
-
Temporal Difference: update the value function from a step, so we replace Gt that we don’t have with an estimated return called TD target (获得一个 action 的 reward 以及对于下个 state 的估计来更新现在 state, 基于 bellman equation)
- \[V(S_t) \leftarrow V(S_t) + \alpha [R_{t+1} + \gamma V(S_{t+1})- V(S_t)]\]
-
-
we have 2 types of value-based functions:
- state-value function $V_{\pi}(s)=E_{\pi}[G_t \mid S_t = s]$ : value of a state
- action-value function $Q_{\pi}(s, a)=E_{\pi}[G_t \mid S_t = s, A_t = a]$ : value of state-action pair
-
Bellman equation:
- \[V_{\pi}{(s)} = E_{\pi}[R_{t+1} + \gamma \times V_{\pi}(S_{t+1}) | S_t = s]\]
- value of state s = expected value of immediate reward + the discounted value of next state
Q-learning
- is off-policy value-based, uses a TD approach
-
Trains Q-Function (an action-value function) which internally is a Q-table that contains all the state-action pair values
- Quality of the action at the state
- 算法伪代码:

-
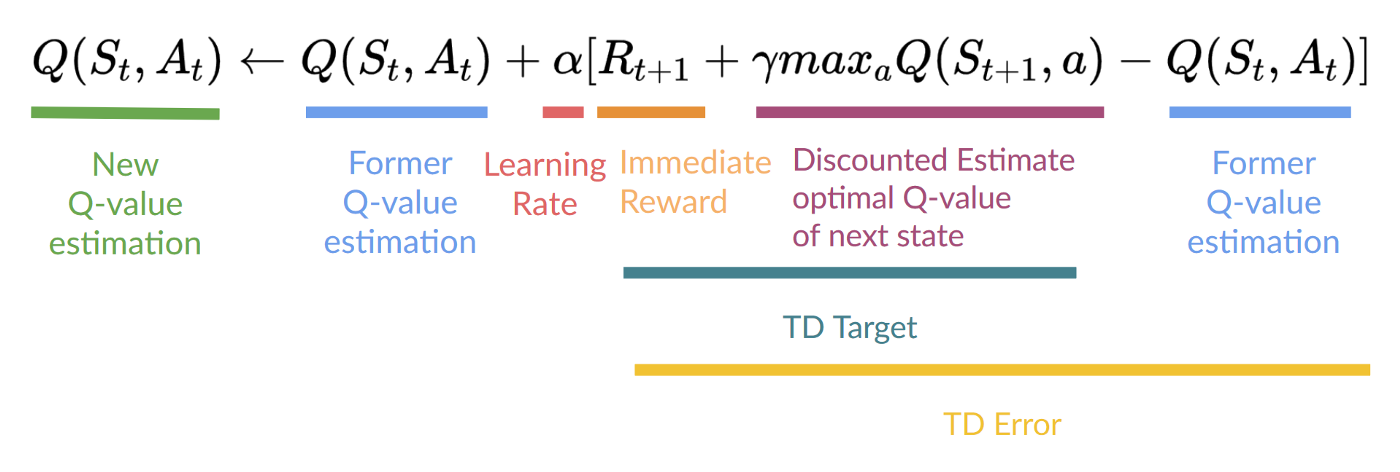
更新公式:注意到 $S_{t+1}$ 的 best state-action pair value 是通过 greedy (updating policy)取到 max,而不是 $\epsilon$-greedy (acting policy),所以是 off-policy
Deep Q-learning
-
loss function that compares Q-value prediction and the Q-target to update DQN
-
Deep Q-learning has 2 phases:
- Sampling: we perform actions and store the observed experience tuples in a replay memory.
- Training: Select a small batch of tuples randomly and learn from this batch using a gradient descent update step.
-
3 solutions to stabilize training:
- Experience Replay to make more efficient use of experiences. 通过 replay buffer 从中不断 sample batches, 多次学习 experience
- Fixed Q-Target to stabilize the training. 因为我们使用估计的 q value of next_state,所以 q-value, target-value 都在不断变化,
- 拆分成 online network, target network,每 n steps copy online network 更新一次 target network
- Double Deep Q-Learning, to handle the problem of the overestimation of Q-values. 因为我们每次 select action 是 max,会导致系统性高估,通过 online network 挑选 action,而 target network 来计算 target q-value of next_state taking that action,因为 2 个 nets 没那么容易同时高估,所以降低了高估的 bias
Policy gradient
-
目标是 parametrize the policy, 直接学这个 policy
-
而 actor-critic 是 a combination of value-based and policy-based methods.
-
policy-gradient 是 policy-based 方法的子集, 特点是 optimize the parameter $\theta$ directly by performing the gradient ascent on the performance of the objective function $J(\theta)$
-
gradient ascent / descent 就是根据函数需要最大化 / 最小化来选
- advantages:
- The simplicity of integration
- Policy-gradient methods can learn a stochastic policy, 不再需要手动实现 exploration/exploitation trade-off,也避免了 perceptual aliasing 感知混叠,即某几个 state 可能是一样的,但是需要执行不同的 action
- Policy-gradient methods are more effective in high-dimensional action spaces and continuous actions spaces, 不再设计连续值取 max
- Policy-gradient methods have better convergence properties 训练变化一般会更平滑,而不会因为 max 而有突变
- disadvantages:
- 经常 converges to a local maximum
- step by step: it can take longer to train
- can have high variance
- objective function:
-
给定一个 trajectory $\tau$ 给出 agent 的 expected cumulative reward
-

-
目标是找到 $\theta$ 来最大化这个目标函数
-
期望来自于不同轨迹的加权求和
-
- Policy Gradient Theorem:
-
-
Reinforce (Monte-Carlo policy-gradient)
-
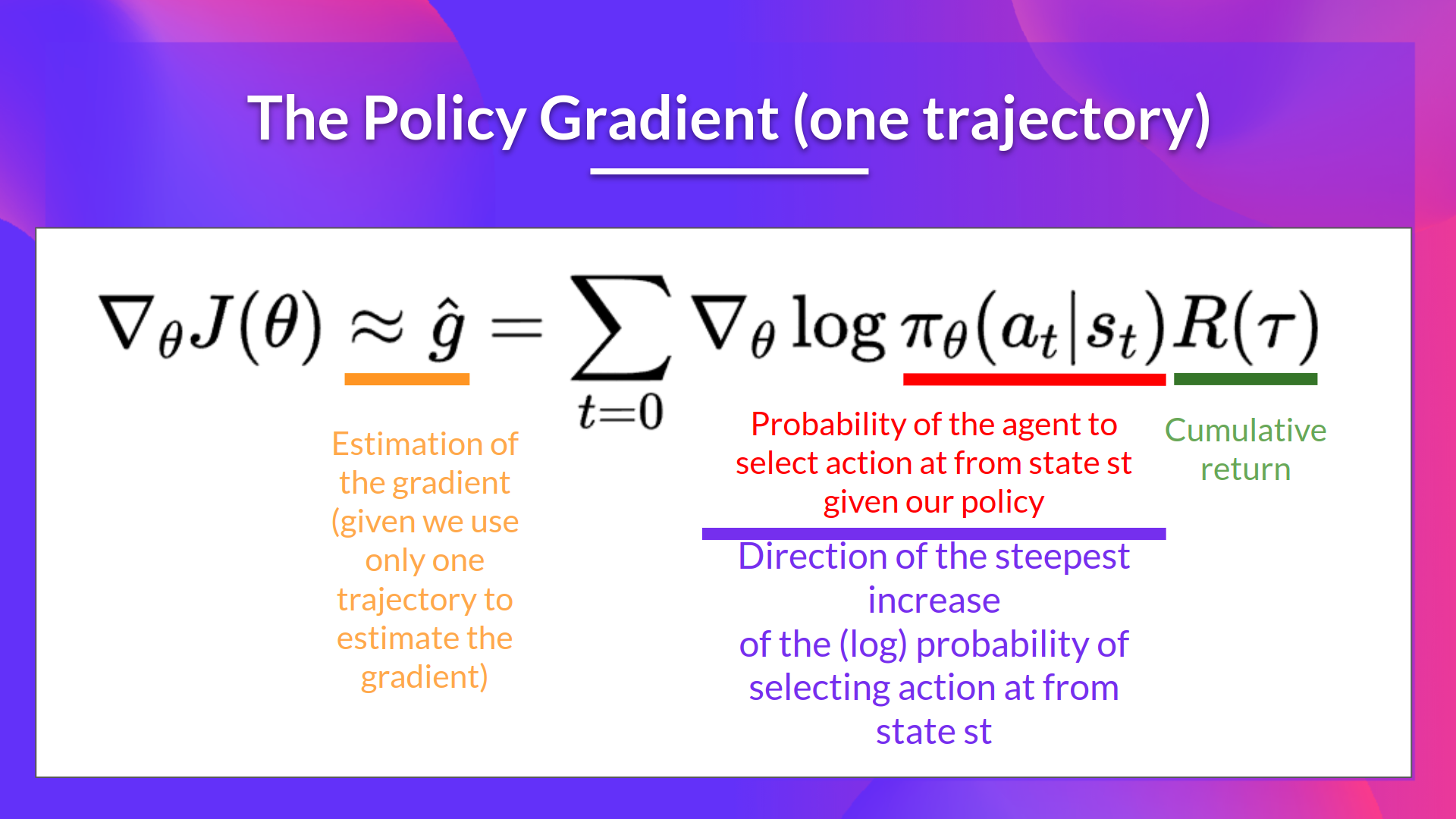
uses an estimated return from an entire episode to update the policy parameter $\theta$
- use the policy to collect an episode $\tau$
- 计算梯度
- 更新 policy weights
-
-
算法伪代码:
-

